第7章 分布式事务.md 35 KB
分布式事务
1.分布式事务问题
1.1.本地事务
本地事务,也就是传统的单机事务。在传统数据库事务中,必须要满足四个原则:
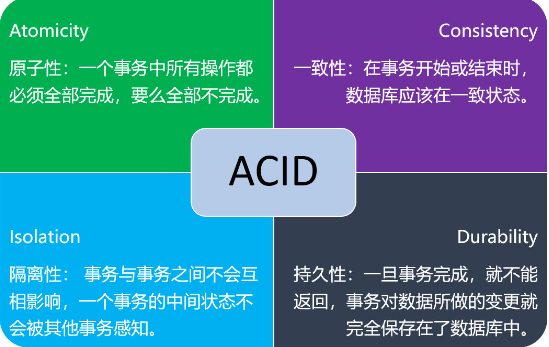
隔离性:设置隔离级别
脏读: ReadUnCommited(读未提交) 并发的事务读取到其他事务未提交数据。 解决脏读:提高隔离级别 ReadCommited
不可重复读:ReadCommited(读已提交) 在一个事务中前后读取数据不一致(对数据修改)。解决不可重复读:提高隔离级别 :ReadRepeatable
重复读:RepeatableRead (幻读:偏向数据的新增,删除)
Serializable:序列化,不允许存在并行事务
1.2.分布式事务
分布式事务,就是指不是在单个服务或单个数据库架构下,产生的事务,例如:
- 跨数据源的分布式事务(一个应用访问多个数据库)
- 跨服务的分布式事务(多个应用对应多个数据库,跨JVM)
- 综合情况
在数据库水平拆分、服务垂直拆分之后,一个业务操作通常要跨多个数据库、服务才能完成。例如电商行业中比较常见的下单付款案例,包括下面几个行为:
- 创建新订单
- 扣减商品库存
- 从用户账户余额扣除金额
完成上面的操作需要访问三个不同的微服务和三个不同的数据库。
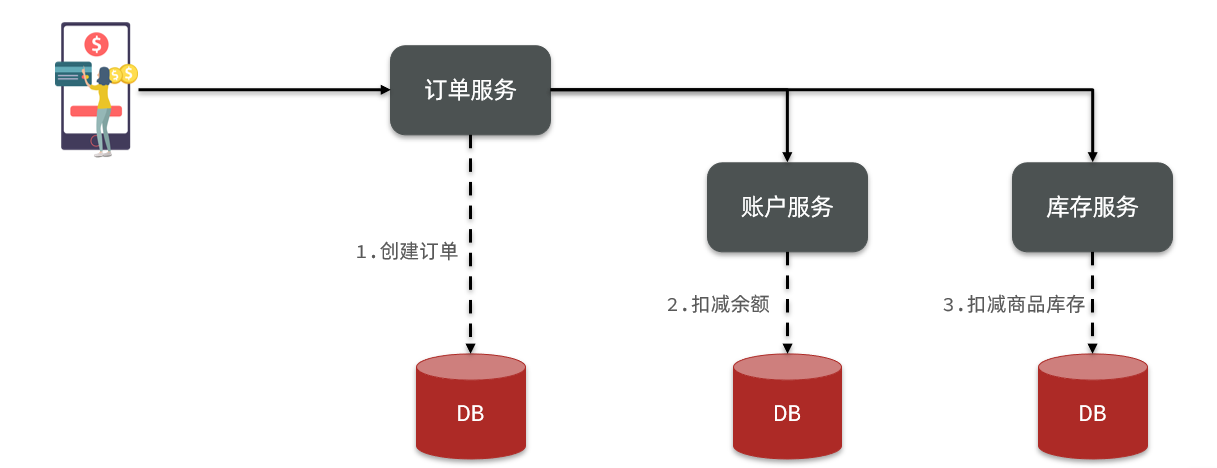
订单的创建、库存的扣减、账户扣款在每一个服务和数据库内是一个本地事务,可以保证ACID原则。
但是当我们把三件事情看做一个"业务",要满足保证“业务”的原子性,要么所有操作全部成功,要么全部失败,不允许出现部分成功部分失败的现象,这就是分布式系统下的事务了。
此时ACID难以满足,这是分布式事务要解决的问题
1.3.演示分布式事务问题
我们通过一个案例来演示分布式事务的问题:
1)导入课前资料提供的SQL文件:

2)导入课前资料提供的微服务:

微服务结构如下:
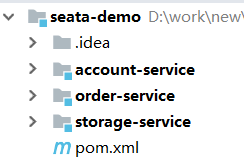
其中:
seata-demo:父工程,负责管理项目依赖
- account-service:账户服务,负责管理用户的资金账户。提供扣减余额的接口
- storage-service:库存服务,负责管理商品库存。提供扣减库存的接口
- order-service:订单服务,负责管理订单。创建订单时,需要调用account-service和storage-service
业务需求:用户提交订单后,扣减商品库存,扣减账户金额。
)测试下单功能,发出Post请求:
请求如下:
http://localhost:7001/order
{
"userId": 1,
"commodityCode": "100101008610050",
"money": 100,
"count": 1
}
如图:
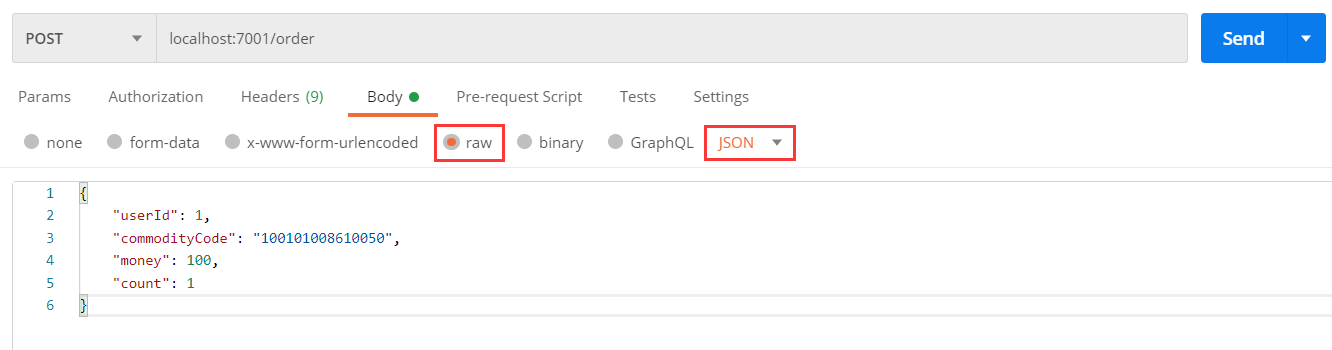
测试发现,当库存不足时,如果余额已经扣减,并不会回滚,出现了分布式事务问题。
2.理论基础
2.1 CAP定理
解决分布式事务问题,需要一些分布式系统的基础知识作为理论指导。
CAP 理论:
CAP 定理(CAP theorem)又被称作布鲁尔定理(Brewer's theorem),是加州大学伯克利分校的计算机科学家埃里克·布鲁尔(Eric Brewer)在 2000 年的 ACM PODC 上提出的一个猜想。对于设计分布式系统的架构师来说,CAP 是必须掌握的理论。
在一个分布式系统中,当涉及读写操作时,只能保证一致性(Consistence)、可用性(Availability)、分区容错性(Partition Tolerance)三者中的两个,另外一个必须被牺牲。
- C 一致性(Consistency):对某个指定的客户端来说,读操作保证能够返回最新的写操作结果
- A 可用性(Availability):非故障的节点在合理的时间内返回合理的响应
(不是错误和超时的响应) - P 分区容忍性(Partition Tolerance):当出现网络分区后
(可能是丢包,也可能是连接中断,还可能是拥塞),系统能够继续“履行职责”-必须满足
CAP特点:
在实际设计过程中,每个系统不可能只处理一种数据,而是包含多种类型的数据,
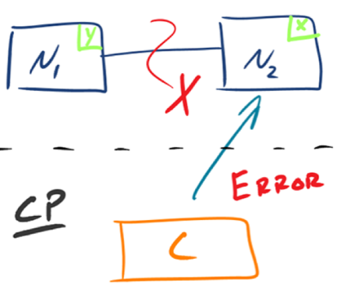
有的数据必须选择 CP,有的数据必须选择 AP,分布式系统理论上不可能选择 CA 架构。- CP:如下图所示,
为了保证一致性,当发生分区现象后,N1 节点上的数据已经更新到 y,但由于 N1 和 N2 之间的复制通道中断,数据 y 无法同步到 N2,N2 节点上的数据还是 x。这时客户端 C 访问 N2 时,N2 需要返回 Error,提示客户端 C“系统现在发生了错误”,这种处理方式违背了可用性(Availability)的要求,因此 CAP 三者只能满足 CP。
- CP:如下图所示,
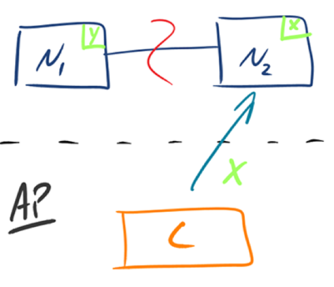
- AP:如下图所示,
为了保证可用性,当发生分区现象后,N1 节点上的数据已经更新到 y,但由于 N1 和 N2 之间的复制通道中断,数据 y 无法同步到 N2,N2 节点上的数据还是 x。这时客户端 C 访问 N2 时,N2 将当前自己拥有的数据 x 返回给客户端 C 了,而实际上当前最新的数据已经是 y 了,这就不满足一致性(Consistency)的要求了,因此 CAP 三者只能满足 AP。注意:这里 N2 节点返回 x,虽然不是一个“正确”的结果,但是一个“合理”的结果,因为 x 是旧的数据,并不是一个错乱的值,只是不是最新的数据而已。
- CAP 理论中的
C 在实践中是不可能完美实现的,在数据复制的过程中,节点N1 和节点 N2 的数据并不一致(强一致性)。即使无法做到强一致性,但应用可以采用适合的方式达到最终一致性。
2.2.BASE理论
BASE理论是对CAP的一种解决思路,包含三个思想:
- Basically Available (基本可用):分布式系统在出现故障时,允许损失部分可用性,即保证核心可用。
- Soft State(软状态):在一定时间内,允许出现中间状态,比如临时的不一致状态。
- Eventually Consistent(最终一致性):虽然无法保证强一致性,但是在软状态结束后,最终达到数据一致。
2.3.解决分布式事务的思路
分布式事务最大的问题是各个子事务的一致性问题,因此可以借鉴CAP定理和BASE理论,有两种解决思路:
AP模式:各子事务分别执行和提交,允许出现结果不一致,然后采用弥补措施恢复数据即可,实现最终一致(柔性事务)。
CP模式:各个子事务执行后互相等待,同时提交,同时回滚,达成强一致。但事务等待过程中,处于弱可用状态(刚性事务)。
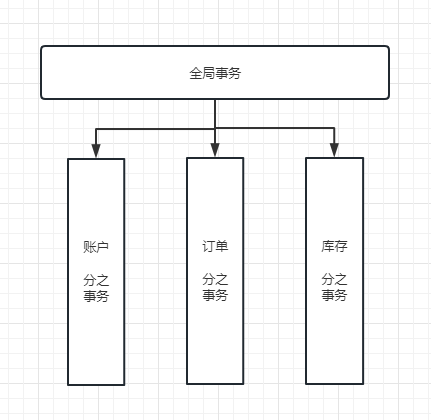
但不管是哪一种模式,都需要在子系统事务之间互相通讯,协调事务状态,也就是需要一个事务协调者(TC):
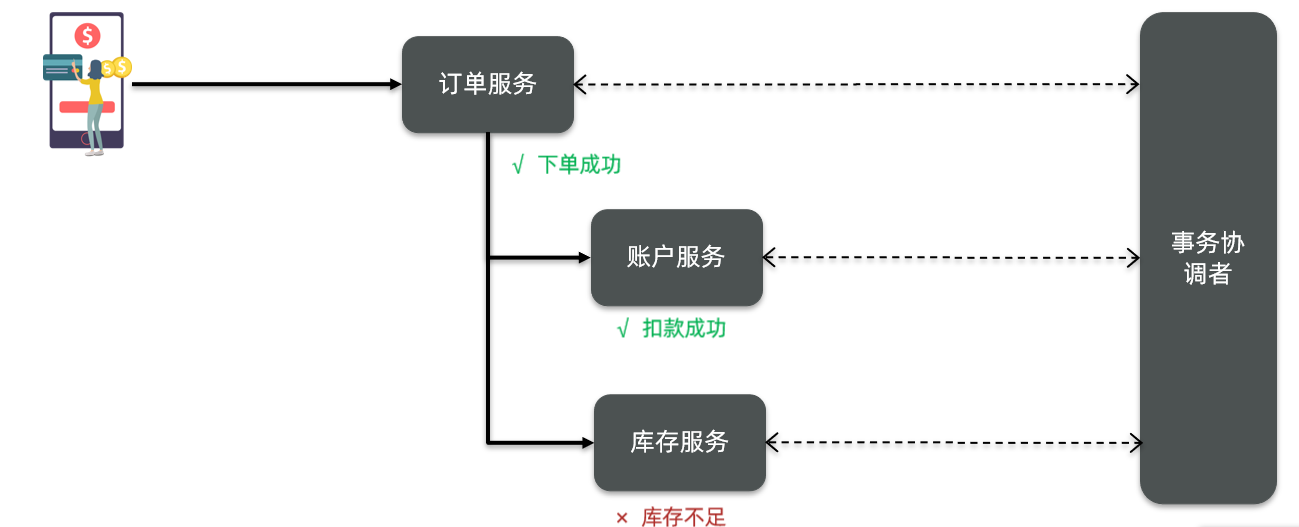
这里的子系统事务,称为分支事务;有关联的各个分支事务在一起称为全局事务。
3.Seata简介
Seata是 2019 年 1 月份蚂蚁金服和阿里巴巴共同开源的分布式事务解决方案。致力于提供高性能和简单易用的分布式事务服务,为用户打造一站式的分布式解决方案。
Seata将分布式事务复杂实现进行封装,交给开发者无代码浸入方式(通过一个注解)就可以解决分布式事务问题。让程序员实现业务功能为主。
官网地址:https://seata.io/zh-cn/,其中的文档、博客中提供了大量的使用说明、源码分析。
Seata 设计理念
Seata 的设计目标是对业务无侵入,它把一个分布式事务理解成一个包含了若干分支事务的全局事务。全局事务的职责是协调其下管辖的分支事务达成一致,要么一起成功提交,要么一起失败回滚。此外,通常分支事务本身就是一个关系型数据库的本地事务。
3.1.Seata的架构
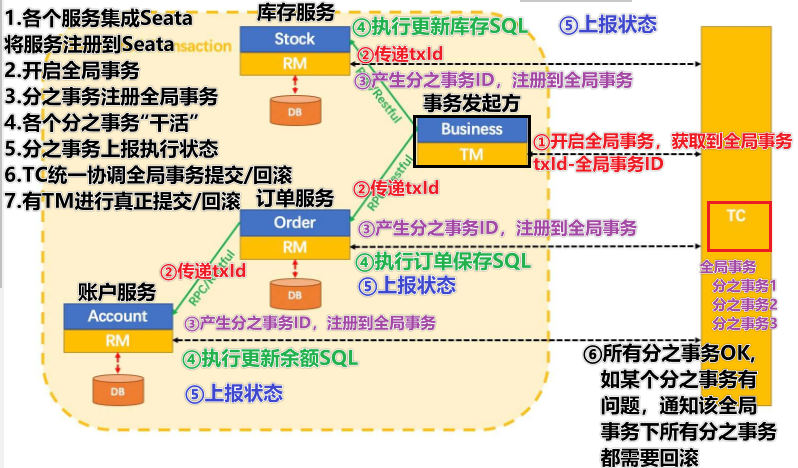
Seata事务管理中有三个重要的角色:
TC (Transaction Coordinator) - 事务协调者(Seata服务):维护全局和分支事务的状态,协调全局事务提交或回滚。
TM (Transaction Manager) - 事务管理器:定义全局事务的范围、开始全局事务、提交或回滚全局事务。
RM (Resource Manager) - 资源管理器:管理分支事务处理的资源,与TC通信以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
整体的架构如图:

Seata基于上述架构提供了四种不同的分布式事务解决方案:
- XA模式:强一致性分阶段事务模式,牺牲了一定的可用性,无业务侵入(CP:刚性事务)
- TCC模式:最终一致的分阶段事务模式,有业务侵入(AP:柔性事务)
- AT模式:最终一致的分阶段事务模式,无业务侵入,也是Seata的默认模式(AP:柔性事务)
- SAGA模式:长事务模式,有业务侵入(AP:柔性事务)
无论哪种方案,都离不开TC,也就是事务的协调者。
3.2 Docker部署Seata(已完成)
3.2.1 Seata数据库
执行以下脚本完成 Seata 数据库创建和表的初始化:https://github.com/seata/seata/blob/1.5.2/script/server/db/mysql.sql
-- 1. 执行语句创建名为 seata 的数据库
CREATE DATABASE seata DEFAULT CHARACTER SET utf8mb4 DEFAULT COLLATE utf8mb4_general_ci;
-- 2.执行脚本完成 Seata 表结构的创建
use seata;
-- the table to store GlobalSession data
CREATE TABLE IF NOT EXISTS `global_table`
(
`xid` VARCHAR(128) NOT NULL,
`transaction_id` BIGINT,
`status` TINYINT NOT NULL,
`application_id` VARCHAR(32),
`transaction_service_group` VARCHAR(32),
`transaction_name` VARCHAR(128),
`timeout` INT,
`begin_time` BIGINT,
`application_data` VARCHAR(2000),
`gmt_create` DATETIME,
`gmt_modified` DATETIME,
PRIMARY KEY (`xid`),
KEY `idx_status_gmt_modified` (`status` , `gmt_modified`),
KEY `idx_transaction_id` (`transaction_id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
-- the table to store BranchSession data
CREATE TABLE IF NOT EXISTS `branch_table`
(
`branch_id` BIGINT NOT NULL,
`xid` VARCHAR(128) NOT NULL,
`transaction_id` BIGINT,
`resource_group_id` VARCHAR(32),
`resource_id` VARCHAR(256),
`branch_type` VARCHAR(8),
`status` TINYINT,
`client_id` VARCHAR(64),
`application_data` VARCHAR(2000),
`gmt_create` DATETIME(6),
`gmt_modified` DATETIME(6),
PRIMARY KEY (`branch_id`),
KEY `idx_xid` (`xid`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
-- the table to store lock data
CREATE TABLE IF NOT EXISTS `lock_table`
(
`row_key` VARCHAR(128) NOT NULL,
`xid` VARCHAR(128),
`transaction_id` BIGINT,
`branch_id` BIGINT NOT NULL,
`resource_id` VARCHAR(256),
`table_name` VARCHAR(32),
`pk` VARCHAR(36),
`status` TINYINT NOT NULL DEFAULT '0' COMMENT '0:locked ,1:rollbacking',
`gmt_create` DATETIME,
`gmt_modified` DATETIME,
PRIMARY KEY (`row_key`),
KEY `idx_status` (`status`),
KEY `idx_branch_id` (`branch_id`),
KEY `idx_xid_and_branch_id` (`xid` , `branch_id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
CREATE TABLE IF NOT EXISTS `distributed_lock`
(
`lock_key` CHAR(20) NOT NULL,
`lock_value` VARCHAR(20) NOT NULL,
`expire` BIGINT,
primary key (`lock_key`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('AsyncCommitting', ' ', 0);
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('RetryCommitting', ' ', 0);
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('RetryRollbacking', ' ', 0);
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('TxTimeoutCheck', ' ', 0);
3.2.2 Seata外置配置
- 在 Nacos 默认的 public 命名空间下 ,新建配置 Data ID 为 seata-server.properties ,Group 为 DEFAULT_GROUP 的配置,配置如下:

获取Seata 配置在线地址:https://github.com/seata/seata/blob/1.5.2/script/config-center/config.txt 仅需修存储模式为db以及对应的db连接配置
#For details about configuration items, see https://seata.io/zh-cn/docs/user/configurations.html #Transport configuration, for client and server transport.type=TCP transport.server=NIO transport.heartbeat=true transport.enableTmClientBatchSendRequest=false transport.enableRmClientBatchSendRequest=true transport.enableTcServerBatchSendResponse=false transport.rpcRmRequestTimeout=30000 transport.rpcTmRequestTimeout=30000 transport.rpcTcRequestTimeout=30000 transport.threadFactory.bossThreadPrefix=NettyBoss transport.threadFactory.workerThreadPrefix=NettyServerNIOWorker transport.threadFactory.serverExecutorThreadPrefix=NettyServerBizHandler transport.threadFactory.shareBossWorker=false transport.threadFactory.clientSelectorThreadPrefix=NettyClientSelector transport.threadFactory.clientSelectorThreadSize=1 transport.threadFactory.clientWorkerThreadPrefix=NettyClientWorkerThread transport.threadFactory.bossThreadSize=1 transport.threadFactory.workerThreadSize=default transport.shutdown.wait=3 transport.serialization=seata transport.compressor=none #Transaction routing rules configuration, only for the client service.vgroupMapping.default_tx_group=default #If you use a registry, you can ignore it service.default.grouplist=127.0.0.1:8091 service.enableDegrade=false service.disableGlobalTransaction=false #Transaction rule configuration, only for the client client.rm.asyncCommitBufferLimit=10000 client.rm.lock.retryInterval=10 client.rm.lock.retryTimes=30 client.rm.lock.retryPolicyBranchRollbackOnConflict=true client.rm.reportRetryCount=5 client.rm.tableMetaCheckEnable=true client.rm.tableMetaCheckerInterval=60000 client.rm.sqlParserType=druid client.rm.reportSuccessEnable=false client.rm.sagaBranchRegisterEnable=false client.rm.sagaJsonParser=fastjson client.rm.tccActionInterceptorOrder=-2147482648 client.tm.commitRetryCount=5 client.tm.rollbackRetryCount=5 client.tm.defaultGlobalTransactionTimeout=60000 client.tm.degradeCheck=false client.tm.degradeCheckAllowTimes=10 client.tm.degradeCheckPeriod=2000 client.tm.interceptorOrder=-2147482648 client.undo.dataValidation=true client.undo.logSerialization=jackson client.undo.onlyCareUpdateColumns=true server.undo.logSaveDays=7 server.undo.logDeletePeriod=86400000 client.undo.logTable=undo_log client.undo.compress.enable=true client.undo.compress.type=zip client.undo.compress.threshold=64k #For TCC transaction mode tcc.fence.logTableName=tcc_fence_log tcc.fence.cleanPeriod=1h #Log rule configuration, for client and server log.exceptionRate=100 #Transaction storage configuration, only for the server. The file, DB, and redis configuration values are optional. store.mode=db store.lock.mode=db store.session.mode=db #Used for password encryption store.publicKey= #If `store.mode,store.lock.mode,store.session.mode` are not equal to `file`, you can remove the configuration block. store.file.dir=file_store/data store.file.maxBranchSessionSize=16384 store.file.maxGlobalSessionSize=512 store.file.fileWriteBufferCacheSize=16384 store.file.flushDiskMode=async store.file.sessionReloadReadSize=100 #These configurations are required if the `store mode` is `db`. If `store.mode,store.lock.mode,store.session.mode` are not equal to `db`, you can remove the configuration block. store.db.datasource=druid store.db.dbType=mysql store.db.driverClassName=com.mysql.jdbc.Driver store.db.url=jdbc:mysql://192.168.200.6:3306/seata?useUnicode=true&rewriteBatchedStatements=true store.db.user=root store.db.password=root store.db.minConn=5 store.db.maxConn=30 store.db.globalTable=global_table store.db.branchTable=branch_table store.db.distributedLockTable=distributed_lock store.db.queryLimit=100 store.db.lockTable=lock_table store.db.maxWait=5000 #These configurations are required if the `store mode` is `redis`. If `store.mode,store.lock.mode,store.session.mode` are not equal to `redis`, you can remove the configuration block. store.redis.mode=single store.redis.single.host=127.0.0.1 store.redis.single.port=6379 store.redis.sentinel.masterName= store.redis.sentinel.sentinelHosts= store.redis.maxConn=10 store.redis.minConn=1 store.redis.maxTotal=100 store.redis.database=0 store.redis.password= store.redis.queryLimit=100 #Transaction rule configuration, only for the server server.recovery.committingRetryPeriod=1000 server.recovery.asynCommittingRetryPeriod=1000 server.recovery.rollbackingRetryPeriod=1000 server.recovery.timeoutRetryPeriod=1000 server.maxCommitRetryTimeout=-1 server.maxRollbackRetryTimeout=-1 server.rollbackRetryTimeoutUnlockEnable=false server.distributedLockExpireTime=10000 server.xaerNotaRetryTimeout=60000 server.session.branchAsyncQueueSize=5000 server.session.enableBranchAsyncRemove=false server.enableParallelRequestHandle=false #Metrics configuration, only for the server metrics.enabled=false metrics.registryType=compact metrics.exporterList=prometheus metrics.exporterPrometheusPort=9898
- **store.mode=db **存储模式选择为数据库
- 192.168.200.6 MySQL主机地址
- store.db.user=root 数据库用户名
- store.db.password=root 数据库密码
3.2.3 获取seata配置
创建临时容器
docker run -d --name seata-server -p 8091:8091 -p 7091:7091 seataio/seata-server:1.7.0创建文件夹为容器挂载目录
mkdir -p /mydata/seata/config复制容器配置至宿主机
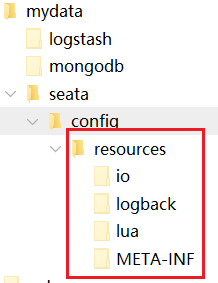
docker cp seata-server:/seata-server/resources/ /mydata/seata/config删除临时容器
docker rm -f seata-server
3.2.4 修改Seata启动配置-启动容器
在获取到 seata-server 的应用配置之后,因为这里采用 Nacos 作为 seata 的配置中心和注册中心,所以需要修改 application.yml 里的配置中心和注册中心地址,详细配置我们可以从 application.example.yml 拿到。
application.yaml配置如下,从课后资料里获取直接覆盖 /mydata/seata/config/resources/application.yml
server: port: 7091 seata: config: type: nacos nacos: server-addr: 192.168.200.6:8848 namespace: group: DEFAULT_GROUP data-id: seata-server.properties security: secretKey: SeataSecretKey0c382ef121d778043159209298fd40bf3850a017 tokenValidityInMilliseconds: 1800000 registry: type: nacos nacos: application: seata-server server-addr: 192.168.200.6:8848 namespace: group: DEFAULT_GROUP cluster: default console: user: username: seata password: seata logging: config: classpath:logback-spring.xml file: path: /mydata/seata/logs- namespace nacos命名空间id,不填默认是public命名空间
- data-id: seataServer.properties Seata外置文件所处Naocs的Data ID,参考上小节的 导入配置至 Nacos
- group: SEATA_GROUP 指定注册至nacos注册中心的分组名
- cluster: default 指定注册至nacos注册中心的集群名
创建容器,必须使用宿主机的Seata配置
docker run -d --name seata-server --restart=always -p 8091:8091 -p 7091:7091 -e SEATA_IP=192.168.200.6 -v /mydata/seata/config/resources:/seata-server/resources seataio/seata-server:1.7.0
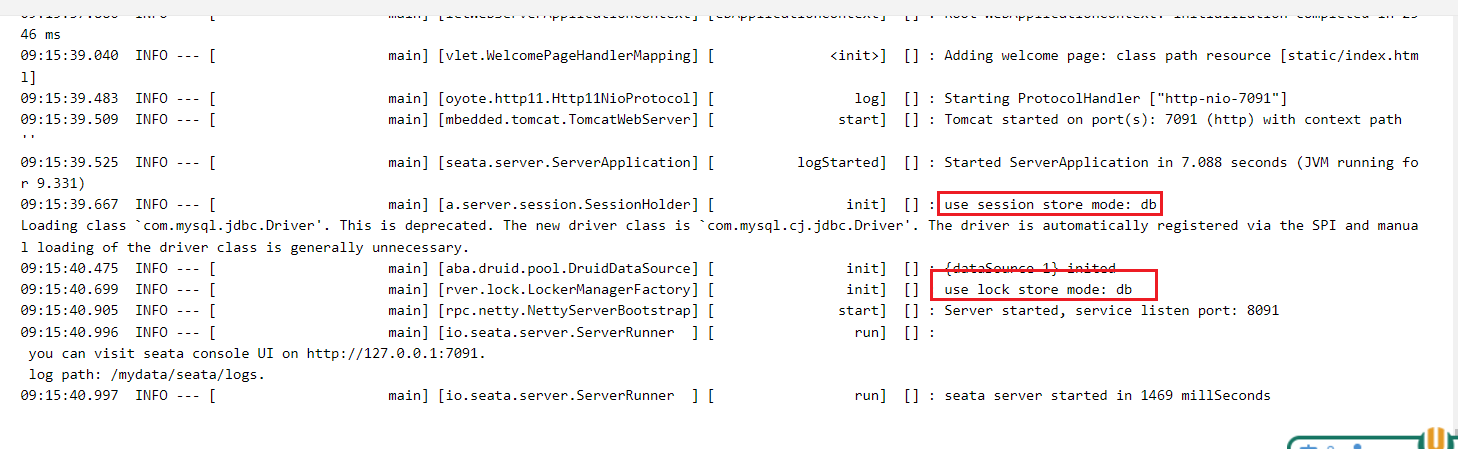
- 通过Nacos验证Seata注册状态http://192.168.200.6:8848/nacos
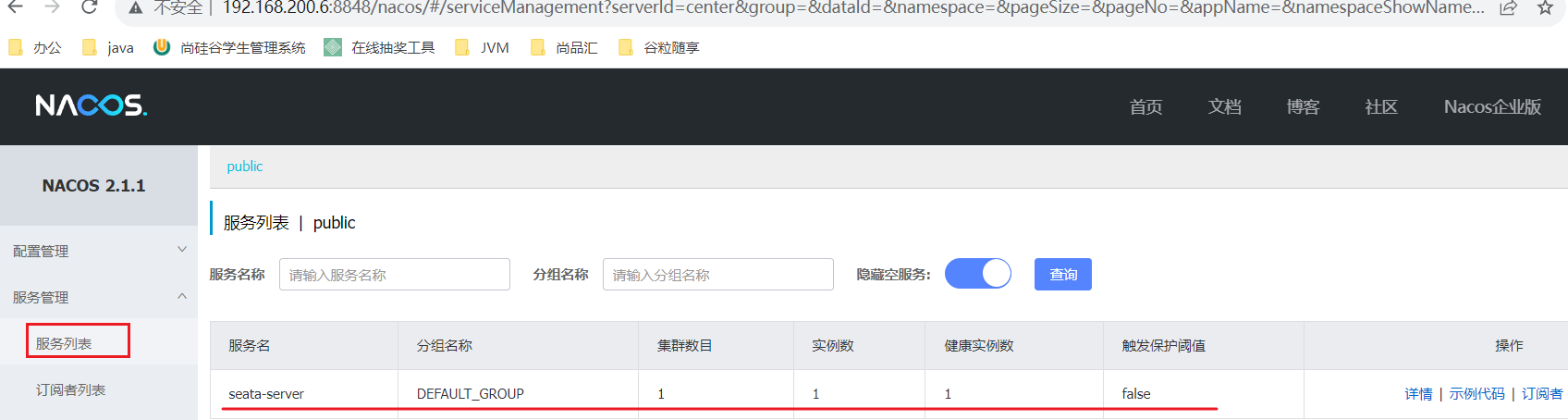
- Seata管理页面 http://192.168.200.6:7091/ 用户名密码:seata/seata
3.3.微服务集成Seata
我们以order-service为例来演示。
3.3.1.引入依赖
首先,在seata-demo父工程中pom.xml中引入依赖,包含子模块全部继承即可:注意:放在dependencies节点中
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.atguigu</groupId>
<artifactId>seata-demo</artifactId>
<packaging>pom</packaging>
<version>1.0-SNAPSHOT</version>
<modules>
<module>order-service</module>
<module>account-service</module>
<module>storage-service</module>
</modules>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.0.5</version>
</parent>
<properties>
<java.version>17</java.version>
<cloud.version>2022.0.2</cloud.version>
<alibaba.version>2022.0.0.0-RC1</alibaba.version>
<mybatis-plus.version>3.5.3.1</mybatis-plus.version>
<mysql.version>8.0.30</mysql.version>
</properties>
<dependencies>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!--seata-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
<!-- 默认seata客户端版本比较低,排除后重新引入指定版本-->
<exclusions>
<exclusion>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>${alibaba.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- Mysql 数据库 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
3.3.2. 配置信息
在
order-service中的application.yml中,配置TC服务信息,通过注册中心nacos,结合服务名称获取TC地址:ps:其它两个微服务也都参考order-service的步骤来做,完全一样。seata: enabled: true tx-service-group: ${spring.application.name}-group # 事务组名称 service: vgroup-mapping: #指定事务分组至集群映射关系,集群名default需要与seata-server注册到Nacos的cluster保持一致 order-service-group: default registry: type: nacos # 使用nacos作为注册中心 nacos: server-addr: 192.168.200.6:8848 # nacos服务地址 group: DEFAULT_GROUP # 默认服务分组 namespace: "" # 默认命名空间 cluster: default # 默认TC集群名称账户微服务
account-service配置文件application.yml 配置Seata信息seata: enabled: true tx-service-group: ${spring.application.name}-group # 事务组名称 service: vgroup-mapping: #指定事务分组至集群映射关系,集群名default需要与seata-server注册到Nacos的cluster保持一致 account-service-group: default registry: type: nacos # 使用nacos作为注册中心 nacos: server-addr: 192.168.200.6:8848 # nacos服务地址 group: DEFAULT_GROUP # 默认服务分组 namespace: "" # 默认命名空间 cluster: default # 默认TC集群名称库存微服务
storage-service配置文件application.yml 配置Seata信息seata: enabled: true tx-service-group: ${spring.application.name}-group # 事务组名称 service: vgroup-mapping: #指定事务分组至集群映射关系,集群名default需要与seata-server注册到Nacos的cluster保持一致 storage-service-group: default registry: type: nacos # 使用nacos作为注册中心 nacos: server-addr: 192.168.200.6:8848 # nacos服务地址 group: DEFAULT_GROUP # 默认服务分组 namespace: "" # 默认命名空间 cluster: default # 默认TC集群名称
微服务如何根据这些配置寻找TC的地址呢?
我们知道注册到Nacos中的微服务,确定一个具体实例需要四个信息:
- namespace:命名空间
- group:分组
- application:服务名
- cluster:集群名
以上四个信息,在刚才的yaml文件中都能找到:
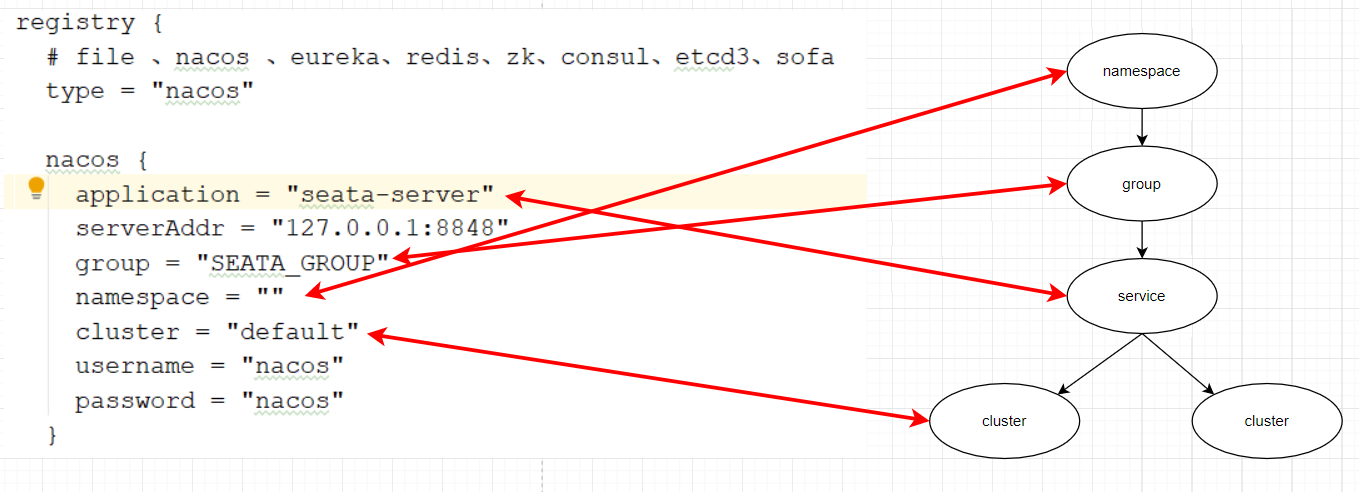
namespace为空,就是默认的public
结合起来,TC服务的信息就是:public@SEATA_GROUP@seata-server@dafault,这样就能确定TC服务集群了。然后就可以通过Nacos拉取对应的实例信息了。
4.实战演练
下面我们使用下Seata不同事务模式。
4.1.XA模式
基于XA协议(规范)两阶段提交解决方案:
XA 规范 是 X/Open 组织定义的分布式事务处理(DTP,Distributed Transaction Processing)标准,XA 规范 描述了全局的TM与局部的RM之间的接口(事务管理器跟数据库之间通信协议),几乎所有主流的数据库都对 XA 规范 提供了支持。
4.1.1.两阶段提交
XA是规范,目前主流数据库都实现了这种规范,实现的原理都是基于两阶段提交。
正常情况:
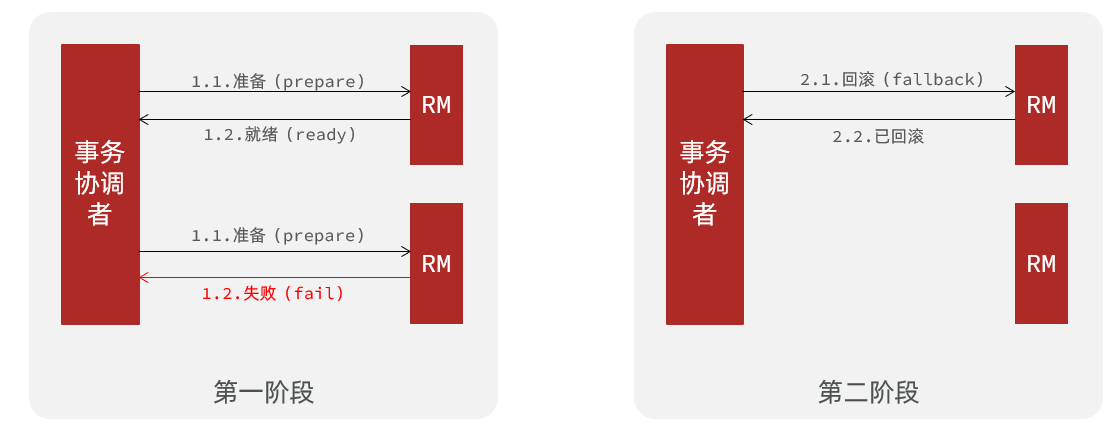
异常情况:
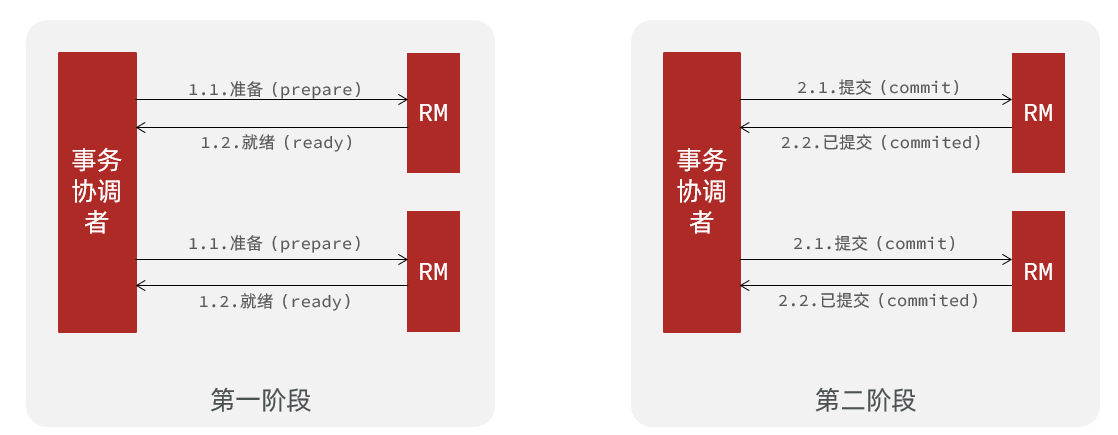
一阶段:
- 事务协调者通知每个事务参与者执行本地事务
- 本地事务执行完成后报告事务执行状态给事务协调者(TC),此时事务不提交,继续持有数据库锁
二阶段:
- 事务协调者基于一阶段的报告来判断下一步操作
- 如果一阶段都成功,则通知所有事务参与者,提交事务
- 如果一阶段任意一个参与者失败,则通知所有事务参与者回滚事务

4.1.2.Seata的XA模型
Seata对原始的XA模式做了简单的封装和改造,以适应自己的事务模型,基本架构如图:
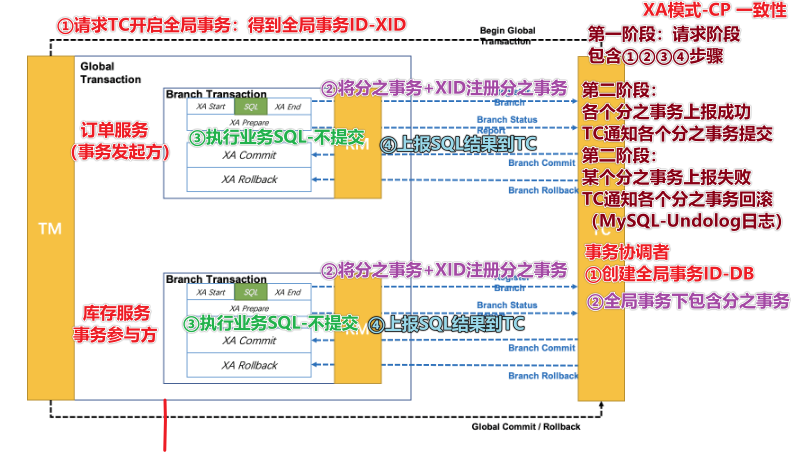
RM一阶段的工作:
① 注册分支事务到TC
② 执行分支业务sql但不提交
③ 报告执行状态到TC
TC二阶段的工作:
- TC检测各分支事务执行状态
a.如果都成功,通知所有RM提交事务
b.如果有失败,通知所有RM回滚事务
RM二阶段的工作:
- 接收TC指令,提交或回滚事务
4.1.3.优缺点
XA模式的优点是什么?
- 事务的强一致性,满足ACID原则。
- 常用数据库都支持,实现简单,并且没有代码侵入
XA模式的缺点是什么?
- 因为一阶段需要锁定数据库资源,等待二阶段结束才释放,性能较差
- 依赖关系型数据库实现事务
4.1.4.实现XA模式
Seata的starter已经完成了XA模式的自动装配,实现非常简单,步骤如下:
1)修改application.yml文件(每个参与事务的微服务),开启XA模式:
seata:
data-source-proxy-mode: XA
2)给发起全局事务的入口方法(事务发起方)添加@GlobalTransactional注解:
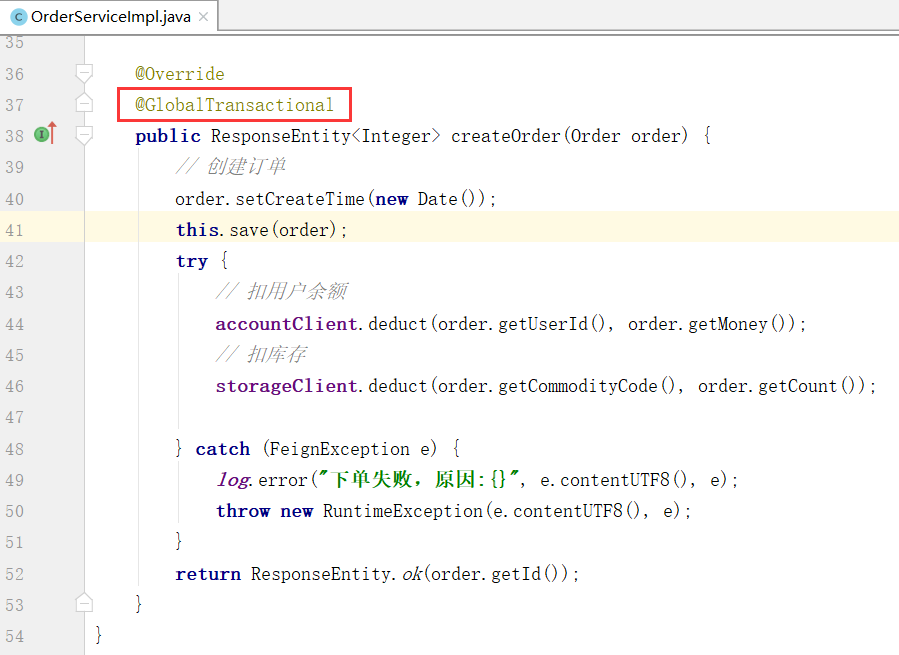
3)重启服务并测试
重启order-service,再次测试,发现无论怎样,三个微服务都能成功回滚。
4.2.AT模式(掌握)
AT模式同样是分阶段提交的事务模型,不过缺弥补了XA模型中资源锁定周期过长的缺陷。
4.2.1.Seata的AT模型
基本流程图:
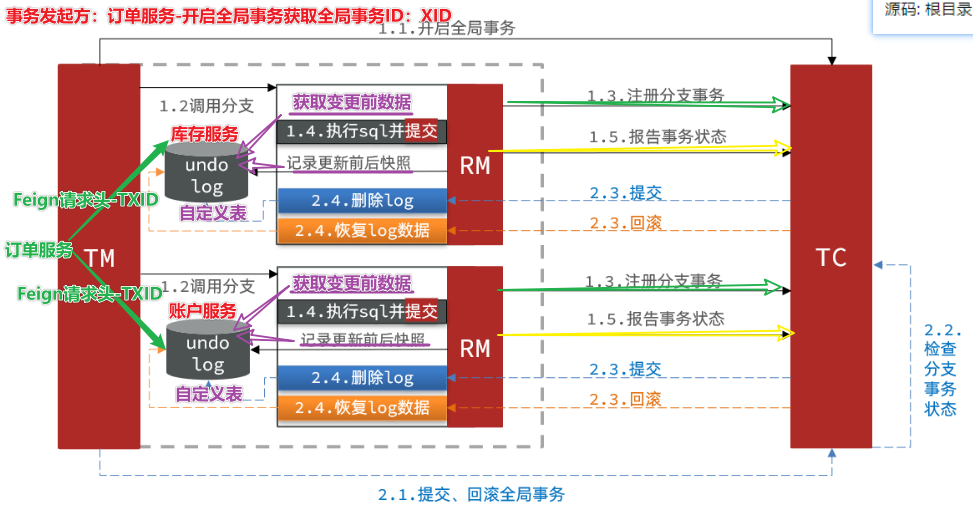
阶段一RM的工作:
- 注册分支事务(将分之事务跟全局事务绑定)
- 记录undo-log 日志表(数据快照)-seata提供表结构
- 执行(业务sql+回滚日志数据)并提交
- 报告事务状态
阶段二提交时RM的工作:
- 删除undo-log即可
阶段二回滚时RM的工作:
- 根据undo-log恢复数据到更新前
4.2.2.流程梳理
我们用一个真实的业务来梳理下AT模式的原理,还是用上面下订单为例中,其中扣减余额分之事务为例
数据库表tb_account,记录用户余额:
| id | money |
|---|---|
| 1 | 100 |
其中一个分支业务要执行的SQL为:
update tb_account set money = money - 10 where id = 1
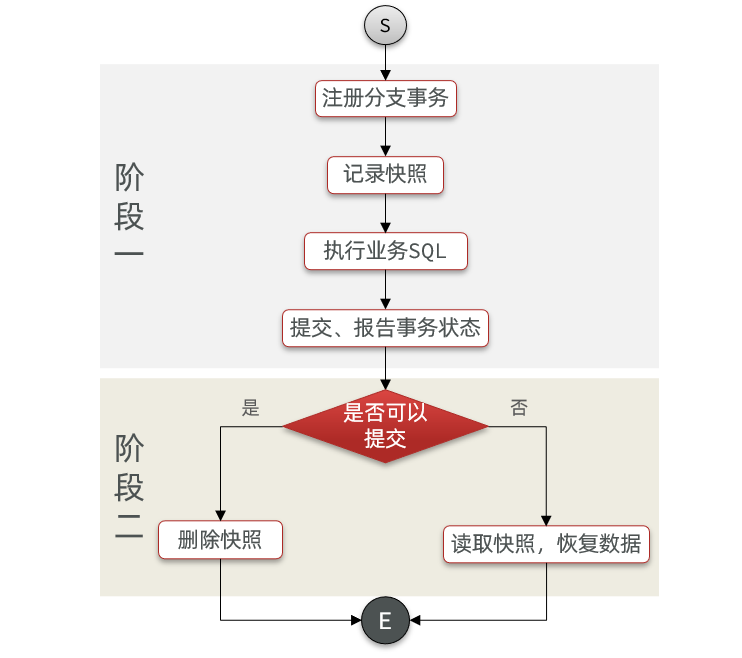
AT模式下,当前分支事务执行流程如下:
一阶段:
1)TM发起并注册全局事务到TC
2)TM调用分支事务
3)分支事务准备执行业务SQL
4)RM拦截业务SQL,根据where条件查询原始数据,形成快照,将快照数据记录到undo_log日志表(seata提供)
{
"id": 1, "money": 100
}
5)RM执行业务SQL,提交本地事务,释放数据库锁。此时 money = 90
6)RM报告本地事务状态给TC
二阶段:
1)TM通知TC事务结束
2)TC检查分支事务状态
a)如果都成功,则立即删除快照(undolog日志表)
b)如果有分支事务失败,需要回滚。读取快照数据({"id": 1, "money": 100}),将快照恢复到数据库。此时数据库再次恢复为100
流程图:
4.2.3.AT与XA的区别
简述AT模式与XA模式最大的区别是什么?
- XA模式一阶段不提交事务,锁定资源;AT模式一阶段直接提交,不会长时间锁定资源。
- XA模式依赖数据库机制(undolog日志文件)实现回滚;AT模式利用数据快照表实现数据回滚。
- XA模式强一致(刚性事务);AT模式最终一致(柔性事务)
4.2.4.脏写问题
在多线程并发访问AT模式的分布式事务时,有可能出现脏写问题,https://seata.io/zh-cn/docs/overview/what-is-seata.html 如图:

Seata解决思路就是引入了全局锁的概念。在释放DB锁之前(提交本地事务前),先拿到全局锁。避免同一时刻有另外一个事务来操作当前数据。

4.2.5.优缺点
AT模式的优点:
- 一阶段完成直接提交事务,释放数据库资源,性能比较好
- 利用全局锁实现读写隔离
- 没有代码侵入,框架自动完成回滚和提交
AT模式的缺点:
- 两阶段之间属于软状态,属于最终一致
- 框架的快照功能会影响性能,但比XA模式要好很多
4.2.6.实现AT模式
AT模式中的快照生成、回滚等动作都是由框架自动完成,没有任何代码侵入,因此实现非常简单。只不过,AT模式需要一个表来记录全局锁、另一张表来记录数据快照undo_log。
1)导入数据库表,记录全局锁
导入课前资料提供的Sql文件:seata-at.sql,undo_log表导入到微服务关联的数据库:db_account、db_order、db_storage三个数据库中分别执行创建undo_log表。
/*
Navicat Premium Data Transfer
Source Server : local
Source Server Type : MySQL
Source Server Version : 50622
Source Host : localhost:3306
Source Schema : seata_demo
Target Server Type : MySQL
Target Server Version : 50622
File Encoding : 65001
Date: 20/06/2021 12:39:03
*/
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for undo_log
-- ----------------------------
DROP TABLE IF EXISTS `undo_log`;
-- 注意此处0.3.0+ 增加唯一索引 ux_undo_log
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of undo_log
-- ----------------------------
SET FOREIGN_KEY_CHECKS = 1;
2)修改三个微服务application.yml文件,将事务模式修改为AT模式即可:
seata:
data-source-proxy-mode: AT # 默认就是AT
3)重启服务并测试
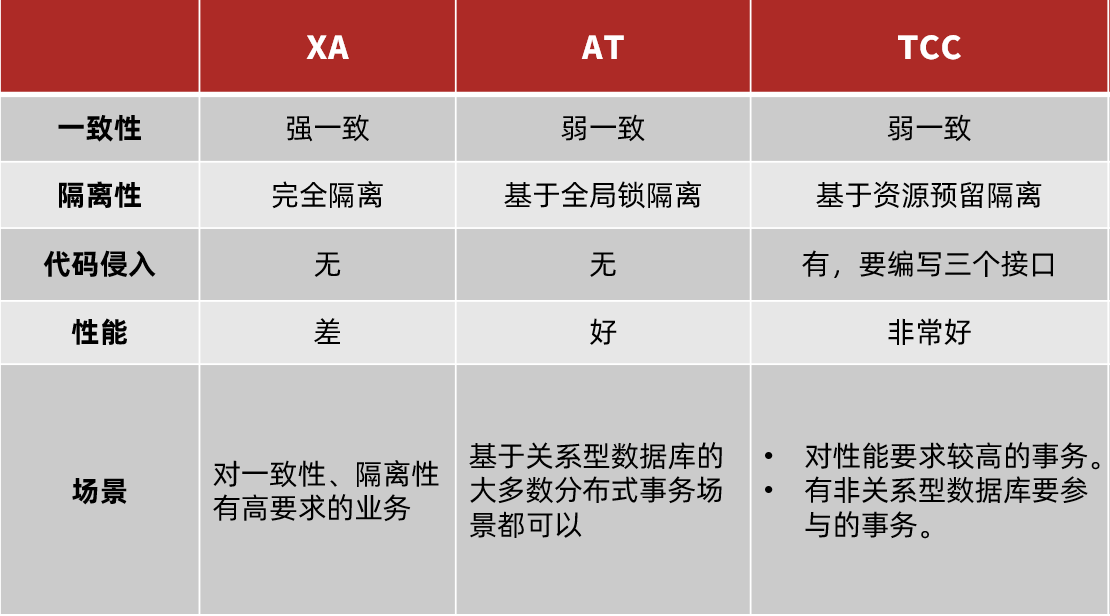
4.3.三种模式对比
我们从以下几个方面来对比四种实现:
- 一致性:能否保证事务的一致性?强一致还是最终一致?
- 隔离性:事务之间的隔离性如何?
- 代码侵入:是否需要对业务代码改造?
- 性能:有无性能损耗?
- 场景:常见的业务场景
如图: